First Look at AlloyDB for PostgreSQL
So 2022 Google I/O is now over, and apart from tons of consumer products, there were some exciting announcements on the Google Cloud front — the introduction and public preview of AlloyDB.
AlloyDB is a fully managed PostgreSQL compatible database service that Google claims to be twice as fast for transactional workload compared to AWS Aurora PostgreSQL.
If you have been working with Google Cloud already, you must be familiar with Cloud SQL for PostgreSQL and Spanner, which offers a PostgreSQL interface, so what's new about this AlloyDB?
AlloyDB at the core is the standard PostgreSQL with changes in the kernel to leverage Google Cloud infrastructure at full by disaggregating compute and storage at every layer of the stack. This architecture allows the storage layer to be more elastic and distributed, better equipped to handle changing workloads, fault-tolerant, and highly available.

AlloyDB also comes with an Intelligent Database Storage Engine; it helps offload many housekeeping operations using the Log Processing System (LPS) to the storage layer. This further increases the throughput for primary instances as they can now focus on the queries rather than the maintenance operations. It also enables intelligent caching, dynamically updating cache based on the most frequent database queries.
Setting Up AlloyDB
Setting up the cluster was intuitive and straightforward; for testing, I created a single node cluster with a read pool, and the overall setup time was approx 15 minutes.
Few things to note here:
- Private Service Access: your VPC where AlloyDB is deployed should have GCP Private Service Access; if you are already using other GCP services like Filestore, MemoryStore, etc. this should be already present.
- Machine Types: one thing to remember here is that machine types are not changeable, so once you select them while creating the cluster, you are stuck with them. It seems this feature will be coming soon — so fingers crossed.
- PostgreSQL Version: AlloyDB locks in the latest version of PostgreSQL at the time of cluster creation, so if you are coming from a Cloud SQL background, you don’t have the flexibility to run a different version of PostgreSQL. The upgrades will be applied automatically by Google as they roll out.
- Accessing the Cluster: since the cluster is deployed in a private network — the easiest way to play around is to set up a bastion or jump server with public IP in your VPC, but ensure you have a secure connection to the GCE instance. If you have data dumps that you want to bring for testing, you might want to consider cloud storage and then access them from your bastion.
- Backups: they are managed and are done at the storage-snapshot level. They are available as on-demand or daily automated backups.
- Low Carbon Locations: it was nice to see some of the locations marked with low CO2 labels suggesting those data centers are running over renewable energy. Though I doubt how impactful it will be as enterprises, don’t choose locations on CO2 emission and more on compliance or consumer group, but it was a nice touch.

Overview
At the core of every AlloyDB PostgreSQL deployment is the cluster; the cluster can contain a single primary instance or an additional standby if HA for read/write to the PostgreSQL database.
The cluster can also have multiple read pool instances that provide the read connection points for the database running in the cluster.
As the top-level resource in AlloyDB, clusters are the central unit of resource management, enabling administrators to monitor performance and configure policies and features across multiple instances.
All cluster resources share a storage layer, which scales as needed.
The storage layer is further composed of 3 parts:
- Regional Log Storage: for writing fast write-ahead logs (WAL)
- Log Processing Service (LPS): for processing these WAL records and producing the database blocks
- Shared Regional Block Storage: for ensuring durability in case of zone storage failure
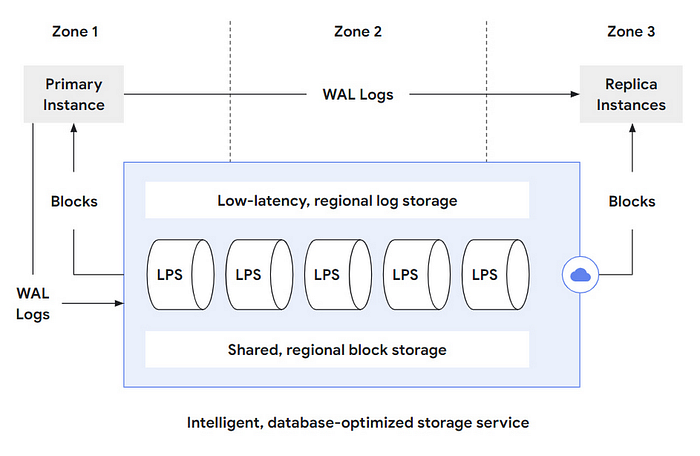
The primary database instance persists WAL log entries and executes the database modification operations like INSERT/DELETE/UPDATE to the regional log store.
The LPS further consumes the WAL for further processing and generates blocks. These blocks are served back to the primary database instance or to any number of replica instances in any of the zones within the region where the storage service operates.
Benchmarks
A real-life application benchmarking to verify the claims to be twice as faster as AWS Aurora DB will need some preparation; I will write a follow-up article with those tests in the coming weeks. But for this first look, I used pgbench for 10 seconds interval to verify transactional improvement as we scale horizontally with more read nodes.
+-----------+--------------------+--------------------------+
| Read Pool Node Count | Transactions per second (TPS) |
+-----------+--------------------+--------------------------+
| 1 | 71428 (including connection) |
| 2 | 148667 (including connection) |
| 4 | 301613 (including connection) |
+-----------+--------------------+--------------------------+Pricing
While in preview, AlloyDB is available at no cost for playing around under the fair usage limit. But once it goes GA or outside of fair usage limits, the pricing will be composed of 3 components:
- CPU and Memory pricing
- Storage pricing
- Networking pricing
CPU and Memory Pricing
Compute resources for AlloyDB are priced per vCPU and GB of memory, which are determined by the VMs in AlloyDB instances. A zonal primary instance uses one VM. A high availability primary instance uses two VMs, one for the active primary and a second for the in-region standby. AlloyDB read pool nodes use one VM each.
When an instance is created, we choose the number of CPUs and the amount of memory we want for its VMs, up to 64 CPUs and 512 GB of memory per VM. Below is the breakdown for Frankfurt (europe-west-3) region:
+-----------+--------------------+---------------------------+
| Frankfurt (europe-west-3) | price (hourly) |
+-----------+--------------------+---------------------------+
| vCPUs | $0.07797 / vCPU hour |
| Memory | $0.01322 / GB hour |
+-----------+--------------------+---------------------------+Storage pricing
Here the intelligent database storage engine comes into play and automatically scales up and down the required storage — so we only pay for the storage we use. The storage cost for Frankfurt (europe-west-3) region is:
+-----------+--------------------+---------------------------+
| Frankfurt (europe-west-3) | price (hourly) |
+-----------+--------------------+---------------------------+
| Regional cluster storage | $0.0004849 per GB |
+-----------+--------------------+---------------------------+Networking pricing
Ingress to AlloyDB for PostgreSQL is free. Egress pricing depends on the destination of the traffic; if it's within the same region, then it's free, but for inter-region, egress traffic from anywhere in Europe to Frankfurt (europe-west-3) would cost us $0.02/GB.
Conclusion
This is a welcome improvement in the database offering of Google Cloud, and this might be an excellent offering to enable enterprises to move their legacy Oracle databases to GCP confidently somewhere in the future.
The complete compatibility with PostgreSQL 14 enables us to use ora2pg right out of the box, making life easier as we no longer need to worry about the changing interfaces. There were improvements in dynamic storage, better caching, and getting rid of IO bottlenecks by autoscaling storage and read replicas. They all are significant steps forward.
But at this stage, this is a relatively new product (not even in GA). Comparing it with AWS Aurora would not be fair as it's not feature-rich yet; the cost savings and performance benefits depend highly on the use case and require a detailed benchmarking. When writing this article, DMS still doesn’t support AlloyDB, but it’s promised to be in the roadmap, and we might see this in the future.
Google has built some fantastic database services like Bigtable and Spanner, which changed the industry for good, and I am excited about how they will build upon this service. With AlloyDB's disaggregated architecture, the dystopian world where I only pay for SQL database per query and the stored data on GCP seems closer than ever.
